一、方案概述
项目简介
本实时数字人解决方案,依托先进的AI驱动与实时渲染技术,可实现高逼真度、低延迟的数字人实时交互与播报。系统支持全流程本地化离线运行,数据安全可控,无需依赖外网环境,能够充分满足金融、政务、政企、教育、医疗行业等对数据安全与隐私合规有严格要求的场景。
产品具备轻量化部署特性,可适配消费级显卡,大幅降低落地成本与技术门槛,同时采用开放兼容架构,支持后续无缝接入更先进的模型与算法能力,实现数字人形象、交互智能与表现力的持续迭代升级,为智能客服、政务宣讲、金融播报、虚拟主持等场景提供稳定、高效、安全的一站式数字人服务。
 >
>
核心优势
- 全场景智能覆盖:适配教培、文旅、政务、医疗、展馆、学校等多领域
- 24小时在线实时互动:语音/文字交互,无服务时段限制
- 大模型+专属知识库:专业问题精准解答
- 无人值守自主服务:自动接待、引导、讲解、留资
目标用户
企业客户、政务应用、自媒体创作者、教育机构、电商直播等
核心能力
- 自定义数字人形象
- 高保真声音克隆
- 实时语音识别与语义理解(ASR+NLP)
- 实时数字人口型同步
- 端到端响应时间 ≤ 2秒
- 支持私有化部署,保障数据安全

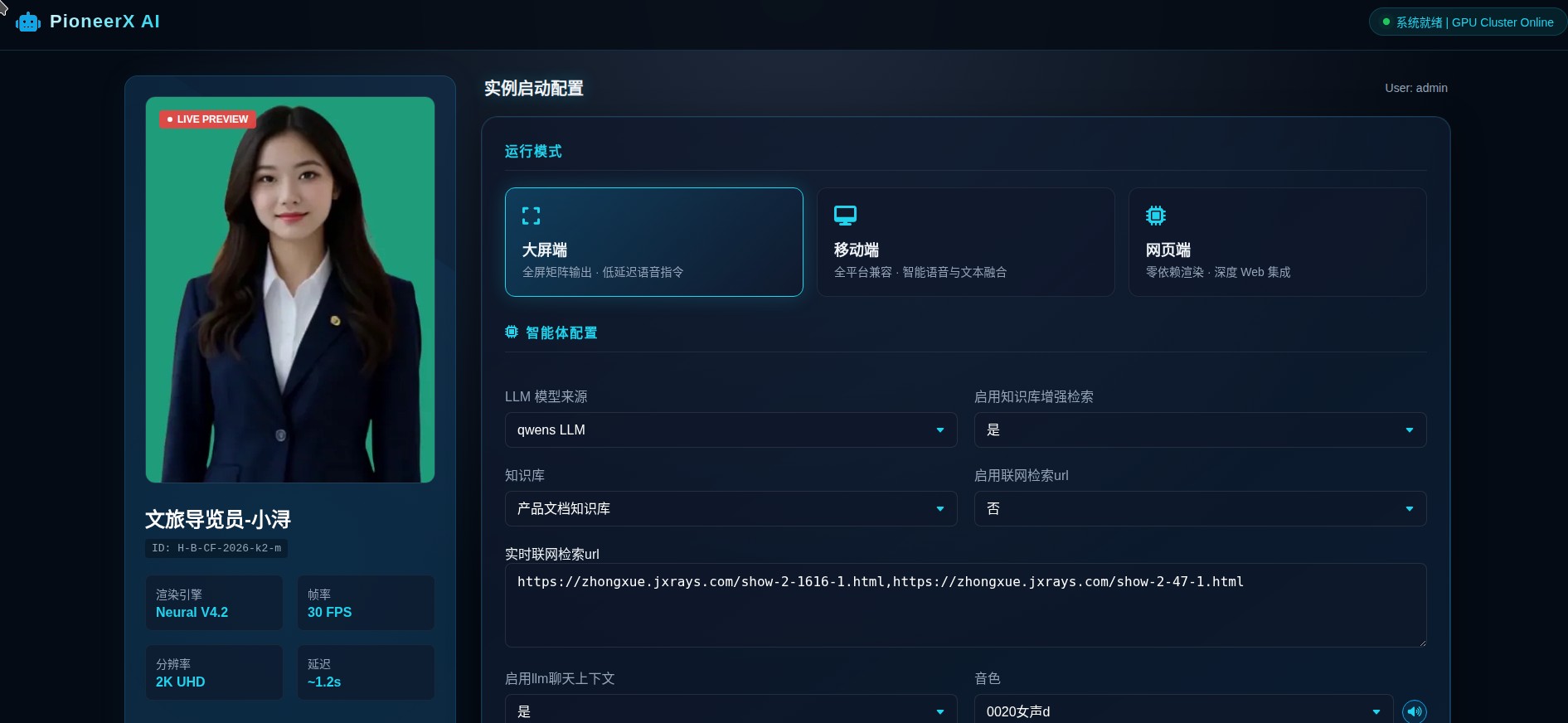
二、功能模块说明
| 模块 | 功能描述 |
|---|---|
| 形象建模引擎 | 支持视频生成实时高清数字人,单张图片转视频素材;静默无动作、说话带动作 |
| 语音识别(ASR) | 中文普通话识别准确率≥98%,支持实时转写 |
| 声音克隆系统 | 3-5秒语音样本即可克隆,效果佳、推理快 |
| 大模型和知识库 | 对接本地大模型、千问系列,支持自定义知识库 |
| 口型渲染与驱动 | 实时口型、表情、肢体驱动;支持大屏、移动端、Web输出 |
三、性能指标
0.8–1.8秒
端到端延迟
<150ms
语音识别延迟
≥25 FPS
渲染帧率
多路并发
单机支持
四、部署方式
内网部署
服务器置于内网,使用本地大模型,数据完全不出网
外网部署
域名穿透+SSL证书,支持本地/远程大模型,安全访问

五、形象/声音克隆与知识库
智能体创建
为数字人设定角色、回复逻辑,自主交互、场景适配
形象克隆
提供清晰面部视频 → 快速生成专属数字人模型
声音克隆
3-5秒清晰音频 → 生成高保真专属音色
知识库搭建
支持Word/Excel/PPT/PDF/TXT/MD/JSON/HTML等,自动向量化,精准问答